An introduction to Enhanced Platform Awareness (EPA) capabilities in OpenStack
A quick introduction to Enhanced Platform Awareness capabilities in OpenStack: NUMA, CPU Pinning, and Huge Pages.


One of the main topics of discussion when architecting an OpenStack cloud to support Telco workloads is around Enhanced Platform Awareness (EPA) capabilities. After all, for an NFV platform to be useful, its virtualized functions must meet or exceed the performance of physical implementations. Some of the EPA features that contribute to the VNF performance are described briefly in this blog post and are fully supported by OpenStack.
Non-Uniform Memory Access (NUMA)
In previous hardware architectures (back in the early days of computing), CPUs ran slower than their memory. That changed considerably with the introduction of more modern architectures, where CPUs operate considerably faster than the memory they use. In this new paradigm, with faster CPUs, if all memory is equally accessible, the result will be that memory access times will most likely be the same regardless of which CPU in the system operates. This design is called Uniform Memory Access (UMA). Then, the need for a new design: Non-Uniform Memory Access (NUMA).
In NUMA, system memory is divided into zones, called nodes, allocated to particular CPUs or sockets. Access to memory local to a CPU is faster than memory connected to remote CPUs on that system. In a NUMA system, each CPU socket will have access to a local memory node faster than a memory in a node that is local to another CPU socket or memory on a bus shared by all CPUs. According to multiple testing for high-performance applications, NUMA misses impacts performance significantly, generally starting at around 10% performance hit or higher.
To mitigate performance degradation, OpenStack compute service (nova) should be configured to make smart scheduling decisions when launching instances to take advantage of NUMA topologies. The main objective is simple, to avoid the penalties associated with CPUs accessing memory that are not local to them.
In the following image, we see a Virtual Machine running without NUMA. In this example, the virtual instance is getting with vCPU (virtual CPU) from CPU_0 in Socket_0 and accessing memory segments local to CPU_1 in Socket_1. The systems need to cross the UPI (Intel Ultra Path Interconnect) and get penalized performance-wise.
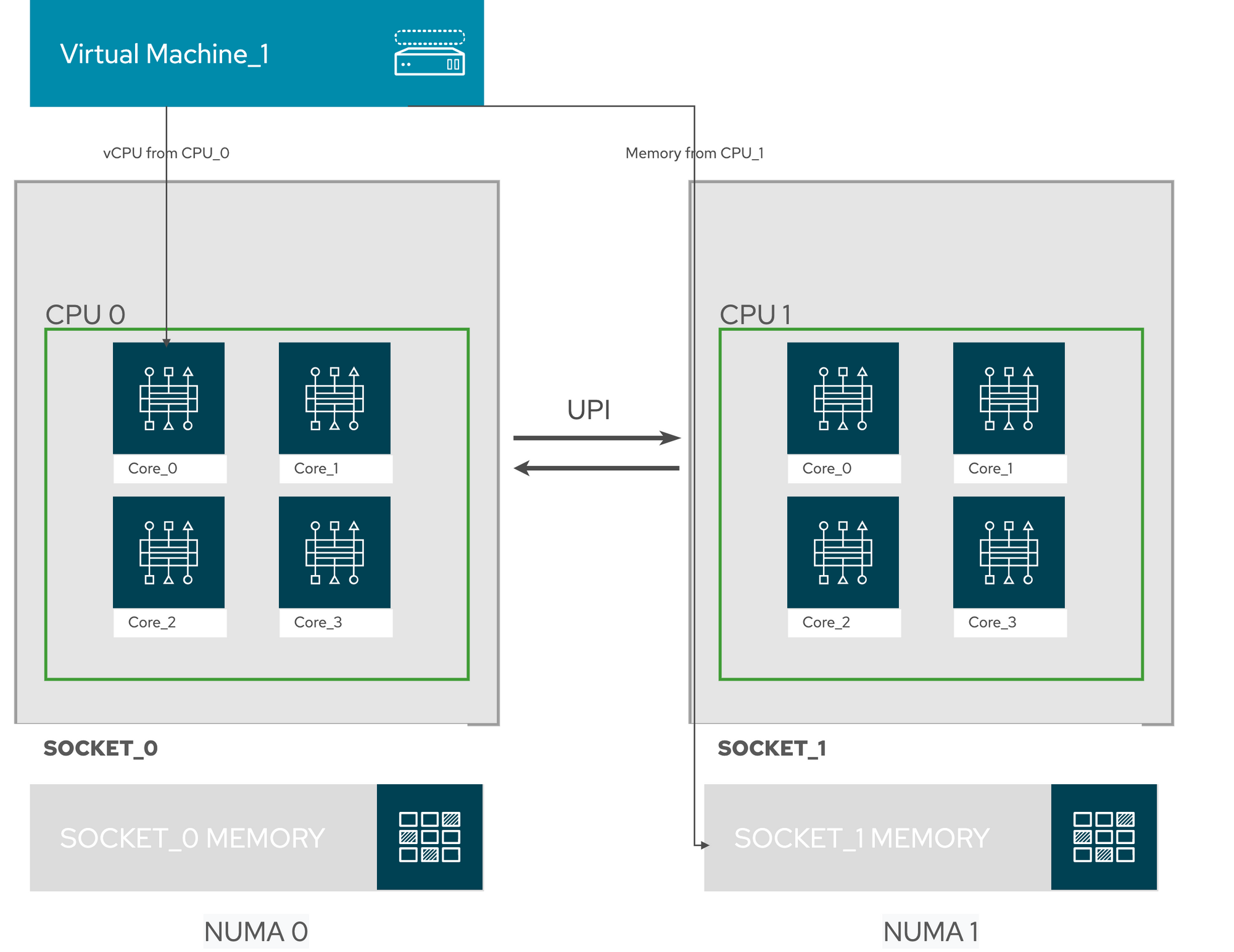
TIP: Not all instances require NUMA to be enabled; these configurations should be used only when the application requires it. Most general type workloads will perform well without NUMA enabled in the system.
In this second image, we see a system that is consuming vCPU and Memory resources from the same CPU. In this topology with NUMA enabled, UPI is not used to access system memory, as the resources are local to the CPU.
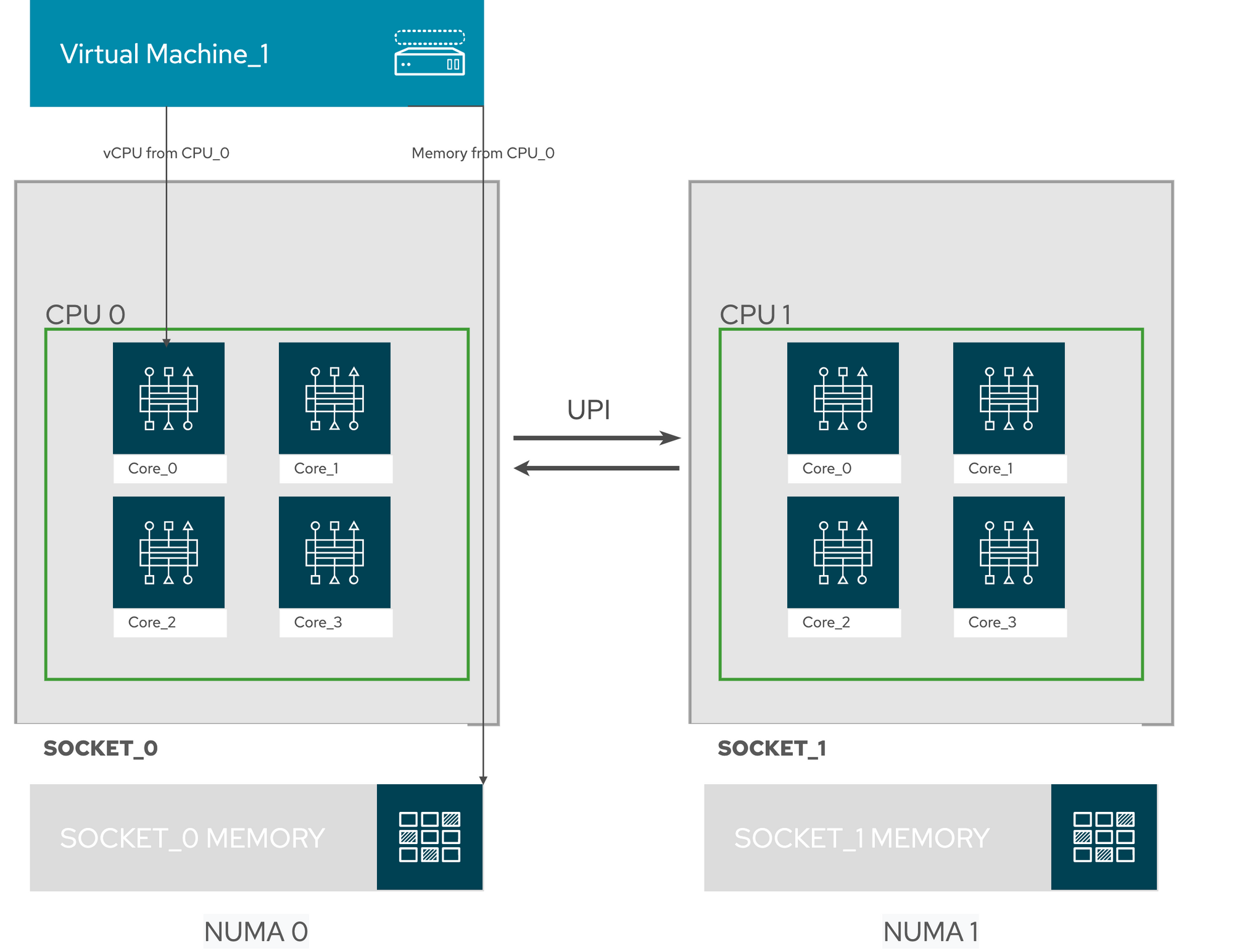
CPU Pinning
The main objective of CPU pinning (sometimes called Processor affinity or cache affinity) is to run a process (in our case, a Virtual Machine) on a specific physical CPU in a given host. Since virtual machines run as userspace tasks on the host operating system, pinning increases cache efficiency. Combining vCPU pinning with numatune can avoid NUMA misses.
By enabling CPU pinning, the operator implicitly is configuring a guest NUMA topology. Each NUMA node of this NUMA topology maps to a separate host NUMA node. The OpenStack operator or administrator must understand the NUMA topology of the host systems to configure CPU pinning and NUMA settings correctly.
Huge Pages
Before we go any further into discussing what Huge Pages are and what is the importance of enabling them, let us talk a bit about how Linux handles system memory. If memory management in Linux could be described in one word, that word should be complex.
In computing, as the processor executes a program, it reads an instruction from memory and decodes it. In this operation of decoding the instruction, it may need to get or store the contents of a location in memory. The processor then executes the instruction and moves onto the next instruction in the program. In this way, the processor is always accessing memory to fetch instructions or fetch and store data.
Linux uses a different approach to manage system memory, using Virtual Memory. In a virtual memory system, all of these addresses are virtual addresses and not physical addresses. These virtual addresses are converted into physical addresses by the processor based on information held in tables maintained by the operating system.
To make this translation, virtual and physical memory is divided into small chunks called pages. By default, Linux on Intel x86 systems it uses 4 Kbyte pages. Each of these pages is given a unique number; the page frame number (PFN).
As described before, the system fetches memory by accessing entire pages instead of individual bytes of memory. This translation happens when the system looks in the Translation Lookaside Buffers (TLB), which contain the physical to virtual address mappings for the most recently or frequently used pages. When a mapping being searched for is not in the TLB, the processor must iterate through all the page tables to determine the correct address mappings. This action causes a performance penalty. Therefore, it is preferable to optimize the TLB to ensure the target process can avoid the TLB misses.
The recommendation to optimize the TLB is to enable Huge Pages. Huge Pages changes from the typical page size of 4KB, to a larger size. Larger page sizes mean that there are fewer pages overall, increasing the amount of system memory that can have it is virtual to physical address translation stored in the TLB, and as a result, lowers the potential for TLB misses, which increases performance.
It is essential to notice that by enabling Huge Pages, there is a potential for memory to be wasted as processes must allocate in pages where not all memory is required. For NFV deployments where page optimization is required, we usually see 1 GB size pages as VNF vendors' recommendation to optimize performance in the application stack.