Architecting your first OpenStack cloud.

![]()
OpenStack is the most popular open-source cloud computing platform to build and manage infrastructure-as-a-service (IaaS) environments. Since its inception in 2010 by Rackspace Hosting and NASA this project has gained popularity and positioned itself as a reliable alternative to proprietary IaaS platforms. Now under the management of the OpenStack Foundation and with more than 30,000 Individual Members from over 170 countries around the world, OpenStack is thriving and increasing its presence in enterprise IT environments.
In this article, I will be sharing best practices for the adoption of OpenStack as your IaaS platform and the necessary steps to take while building your cloud. In my experience, thorough planning is an essential ingredient for a successful cloud initiative.
Identify your Business Objectives
Adoption in an enterprise implies an investment of people and money. A company should never adopt a new technology or software because is “cool” or “trendy”. I have seen projects fail because the decision was not made thinking on the use of cases and business objectives.
As the first rule to adopt OpenStack you should ask yourself two vital questions:
- What are my business drivers for adopting OpenStack?
- Which use cases will OpenStack address?
By doing this, you will know if it makes sense to perform the necessary investment to run an OpenStack cloud.
Identifying your workloads, the “Pets vs. Cattle” dilemma on OpenStack
After a decision has been taken to adopt OpenStack, the next step should be to identify the workloads to run on it.
In the cloud computing world, most use the analogy of “Pets vs. Cattle” to determine the types of workloads and if they should run or not on a cloud platform.
This analogy indicates that “pets” workloads are unique and valuable applications, usually monolithic. In the other hand, “cattle” workloads are mostly identical and commodity-like, with multiple “cattle” instances forming one application.
Some cloud architects will tell you that OpenStack is designed to run only “cattle” workloads, even when this is mostly true, OpenStack as a software has matured and evolved since its creation.
With the right architecture and the correct operational practices and procedures, you should be able to run both types of workloads.
Nevertheless, it is critical that you identify the type of workloads that will be running on your cluster, as this will dictate the architecture and operational practices to consider during and post implementation.
Sizing
After you have identified the workloads to move to the OpenStack cloud you should have a comprehensive list that includes: type, disk, CPU, memory, and criticality. An example is shown in the table below:
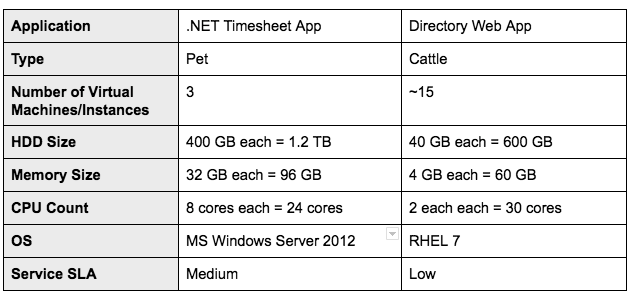
In OpenStack, as with other IaaS clouds, it is a good idea to start small and grow if needed. To do this is important that you know from a capacity planning point of view what will be the capacity required on day one and what will be the expected growth rate. This will determine the size of your initial cloud deployment and also when the cluster should be expanded.
The sizing considerations should be taken for 4 four main components for your cluster:
- Compute requirements
- Memory requirements
- Storage requirements
- Network requirements
It will determine the number of compute nodes (CPU/memory), storage size, and network throughput.
But this is only half of the equation; you will need to plan also the size of your control plane on OpenStack. This planning is influenced by the compute requirements, the number of users, number of instances, network type and availability (SLA).
Hardware selection and storage backend
Part of the planning stage will include the selection of the hardware. Most of my customers use enterprise class servers from vendors like Dell, HP, Cisco, and Lenovo. It is important that you choose a provider that will give you an excellent balance of cost, features, and the support that you need.
My recommendation is to select different server hardware based on cluster roles for your first OpenStack cloud, e.g.,
- Control plane: enterprise class servers.
- Compute nodes: commodity servers.
- Storage nodes: commodity servers.
Another important choice is the selection of the storage backend for your cluster. Some of the most used and traditional storage backends for OpenStack are Ceph and NFS. For both, you could use commodity hardware or use your existing NAS/SAN if they have a supported cinder driver. You could also use a combination of storage backends, based on different use cases and or functions like:
- Image storage (Glance)
- Volume storage (Cinder)
- Ephemeral instance storage (Nova)
Network planning
I like to divide network planning in two for OpenStack clouds:
- Cluster infrastructure network
- Tenant network
Cluster Infrastructure Network
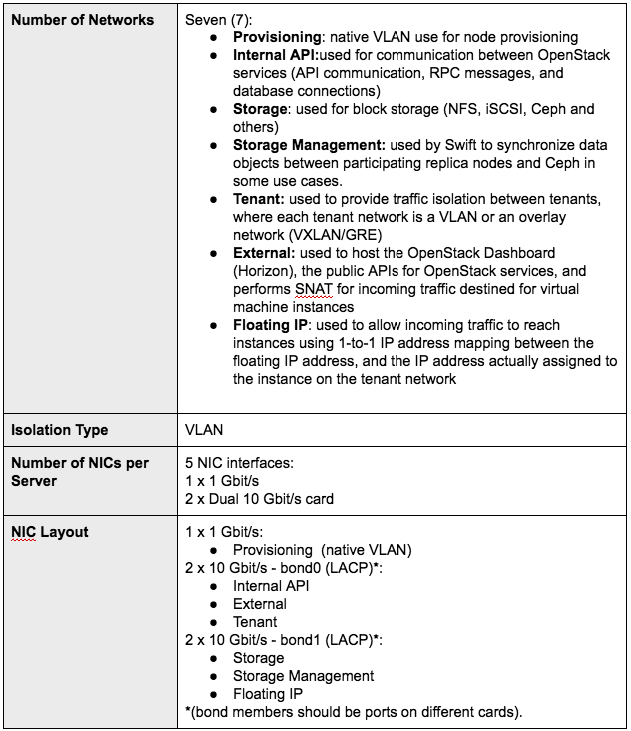
This is the network that will connect the different cluster nodes and provide network isolation for your cloud. When planning this network there are three things to consider:
- Number of networks and isolation type
- Number of NIC per server and uplink speed
- NIC layout (teaming or bonding requirements)
Here is an example that illustrates the cluster infrastructure network for a production-ready OpenStack cloud:
Tenant Network
Because OpenStack is a multi-tenant platform, multiple users should be able to be on the same cluster using shared resources like compute, storage and networking and not be aware that the other user resides on the same platform.
In OpenStack, the tenant network will provide network isolation between projects (tenants), this is possible because Neutron provides each tenant with their networks using either VLAN segregation or overlay networks based on VXLAN or GRE tunneling.
Selecting what technology will be used to provide tenant isolation is a major step in the design. This decision will impact not only the cluster configuration but also the network infrastructure design.
There are four different types of tenant networks:
- Flat: Instances reside on the same network, which can also be shared with the hosts. No VLAN tagging or other network segregation takes place.
- Local: Instances reside on the local compute host and are effectively isolated from any external networks.
- VLAN: Allows users to create multiple provider or tenant networks using VLAN IDs (802.1Q tagged) that correspond to VLANs present in the physical network.
- Tunneling (VXLAN and GRE): Use network overlays to support private communication between instances. A Networking router is required to enable traffic to traverse outside of the GRE or VXLAN tenant network.
There is also another tenant network category named provider networks. These networks map to existing physical networks in the data center. Useful types in this category are flat (untagged) and VLAN (802.1Q tagged).
For more details visit: http://docs.ocselected.org/openstack-manuals/kilo/networking-guide/content/tenant-provider-networks.html
From the above, you should use VLAN or VXLAN/GRE tenant networks. And in your first OpenStack cluster, I do recommend the use of tunneling based tenant networks. By using this method, you will simplify the installation, configuration, and complexity of the cloud.
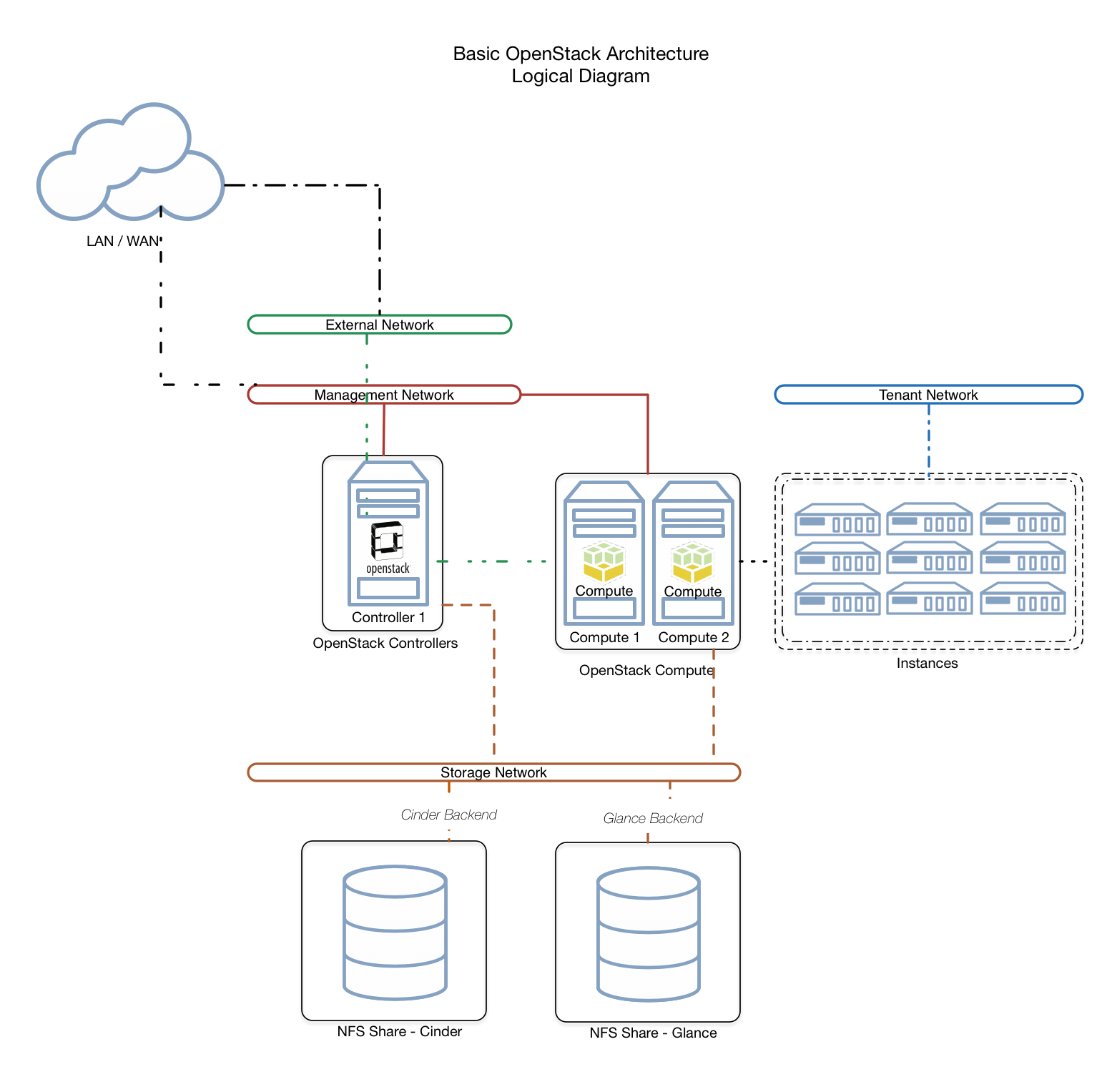
Basic OpenStack architecture
The diagram below illustrates a basic OpenStack Architecture. This architecture could be comprised of the following OpenStack services and cluster components.
OpenStack Services:
- OpenStack Compute (Nova)
- OpenStack Networking (Neutron) and Open vSwitch
- OpenStack Image Service (Glance)
- OpenStack Identity (Keystone)
- OpenStack Dashboard (Horizon)
- OpenStack Volume Service (Cinder)
- MariaDB
- RabbitMQ
Cluster components:
- 1 x OpenStack Controller
- 2 x Compute nodes
- NFS backend for Cinder and Glance
Highly Available OpenStack architecture
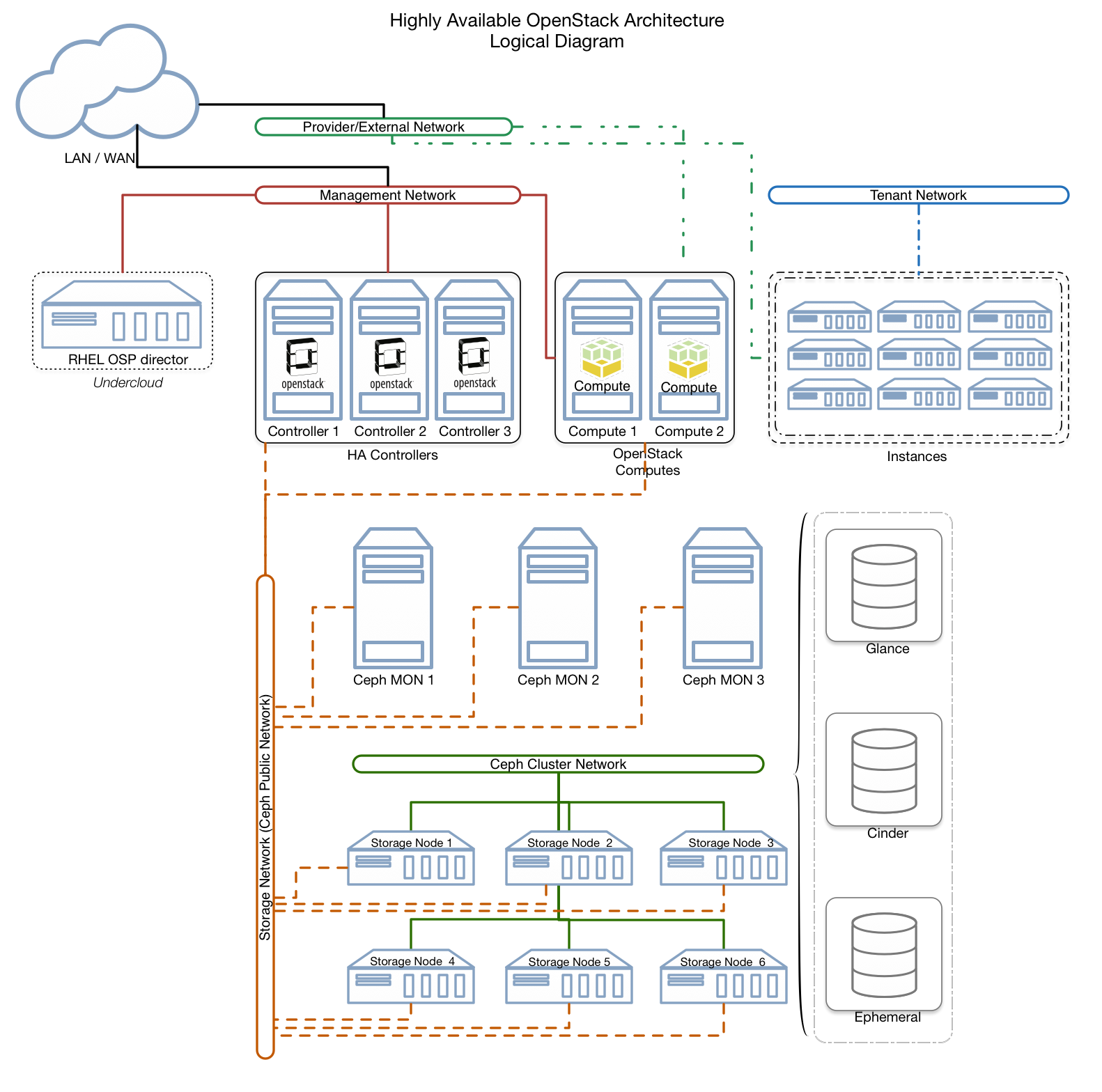
The diagram below illustrates a Highly Available (HA) OpenStack Architecture. This architecture could comprise of the following OpenStack services and cluster components.
OpenStack Services:
- OpenStack Compute (Nova)
- OpenStack Networking (Neutron) and Open vSwitch
- OpenStack Image Service (Glance)
- OpenStack Identity (Keystone)
- OpenStack Dashboard (Horizon)
- OpenStack Volume Service (Cinder)
- MariaDB
- RabbitMQ
Cluster components:
- 1x OpenStack installer (Red Hat OpenStack Platform director)
- 3 x OpenStack Controllers on a High Availability (HA) configuration
- 2 x Compute nodes.
Ceph storage cluster as a backend for cinder, glance, and ephemeral storage.
- 3 Ceph Storage Monitors
- 3 Ceph Storage OSD Servers
- 3 Storage pools:
- Ephemeral (nova)
- Image (Glance)
- Volume (cinder)
In this case, we are using Ceph to be the storage provider for OpenStack, but you could substitute this with NFS storage and for the volume service (cinder) with any SAN/NAS that has a certified driver.
Now you should be ready to architect and deploy your first OpenStack cloud, good luck on your journey.