Ansible and Ansible Tower: best practices from the field
One of my favorite open source projects in the last couple years is Ansible. In this article, I want to share some recommendations based on the first-hand experience in the field.


“Automation is not magic” --me

One of my favorite open source projects in the last couple years is Ansible. Things got even more interesting for me after Red Hat (my employer) acquired the software in 2015 and I got to architect, deploy and write Ansible roles and playbooks as part of my day-to-day. In this article, I want to share some recommendations based on first-hand experience in the field.
But before we start, what is Ansible?
- Created by Michael DeHaan
- Open source software is written in Python (https://github.com/ansible/ansible)
- Modules can be written in any language that can return JSON
- YAML configuration files (easy to read, write and maintain)
- A simple automation engine that automates:
- Cloud provisioning, configuration management, application deployment, network devices, infra-service orchestration, and many other IT needs
- Designed for multi-tiered deployments since day one, modeling IT infrastructure by describing how all systems interrelate
- Agentless, SSH-based
- Idempotent by design: f(x) = f(f(x))
What Ansible is not :

Why?
- You must know what you are doing when you write playbooks, roles and modules
- It’s not for all cases. You must ask yourself, “Can I do it in Ansible?” and “Should I do it in Ansible?”
- Requires a SSH connection
- Ansible is not programming language (it’s meant to be declarative! Where each task represents a desired state)
Here are some of the "best practices" to consider while using Ansible and Ansible Tower:
- Must Use a Version Control System
- A version control system (VCS) allows users to manage the changes to source code and keeps track of every modification. Some examples of VCS are Git, SVN,and Mercurial
- Ansible does not require the use of a VCS, but it’s highly encouraged
- Storing Ansible code in a VCS and adopting software development methodologies is key to create a scalable automation model
- Scalable:
- Share code and collaborate between teams
- Distributed testing
- Multiple life cycle environments for the Ansible code (i.e dev, test, qa & prod)
- CI/CD pipeline integration and unit testing
- Playbook Repository Structure
One of the issues that we see in the field is the playbook repository structure. You must create a structure that works with both Ansible Core and Ansible Tower.
Here is an example of a repository structure:
playbookrepo
|-- groupvars
|----- all.yml
|----- dev.yml
|----- qa.yml
|----- prod.yml
|-- inventory
|-- library
|-- roles
|----- rolename.yml
|-- ansible.cfg
|-- testplaybook.yml
|-- deploylamp.yml
|-- updatesystem.yml
Some notes about this layout:
- ansible.cfg is at the root of the repository. It allows you to keep version control on the basic Ansible settings.
- groupvars defines the group variables for the playbooks
- The inventory is ignored when using Ansible Tower
- A best practice is to have a playbook repository structure by team. For example, Infrastructure, App_1, App_2, Patching
- In this example, there are no roles in the repository /roles directory. A best practice is to separate “roles” into its own repository so they can version controlled, shared and life cycle independently of other playbooks
- Use and create Roles
Roles are a way of automatically loading specific vars_files, tasks, and handlers based on a known file structure. Grouping content by roles also allows for easy sharing with other users. Here are a couple best practices around roles:
- A repository should be created by each role. This allows you to share an individual role with Ansible Galaxy or with other Playbook repositories inside your organization
- You should be able to perform unit testing in each role in a CI model
- A convenient way to test roles is by using containers. This will allow you to test the role across multiple distributions
- Virtual machines are recommended to test roles when the role is performing low level actions like bootloader setting, kernel parameters, firewall settings
- Use the ansible-galaxy command to create the role structure:
ansible-galaxy init role_name --offline - A .gitignore file should be used to ignore every role inside a playbook repository and allow them to be managed individually with a VCS.
- Use YAML properly
- Here are some formatting guidelines to follow when writing Ansible playbooks and roles:
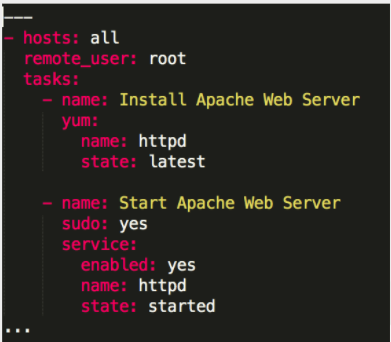
- Every playbook should begin with 3 (three) dashes
“---”and end with 3 (three) dots“...”. This does not apply to files inside roles - Indentation is important! Each line should be indented with two spaces underneath it’s parent
- You should leave exactly one blank line between the tasks and zero inside of the tasks. You should also separate “plays” by using two blank lines
- When writing a task, avoid using a one-line syntax in your playbook. Not only are they ugly, they are difficult to read
- Variables should be unique to each role, descriptive and a name convention should be used, i.e: mysql_dnsname1
Here is an example of the use of Identation and proper formating in a playbook:
-
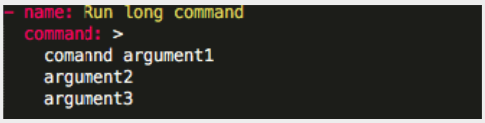
Only use Folded Scalars “>” to separate arguments on each line inside a long shell or command:
-
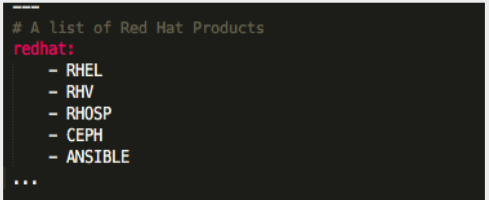
All members of a list are lines beginning at the same indentation level starting with a "- " (a dash and a space) :
You should be able to verify the syntax of your playbooks and role by using --syntax-check.
More examples at http://docs.ansible.com/ansible/latest/YAMLSyntax.html
- Use the following development best practices
- Define the state parameter. In some modules this could be: present, latest, absent, etc.
- Verify that the service you started is actually running! Because you declared it in a playbook does not mean that it is working. You could do this in your playbooks by using “uri”, “waitforconnection” or any other validation method
- Ensure that every play has a “name” variable set with a meaningful name. This will facilitate others to read and understand your code
- Define and use tags to target plays during the execution
- Do not store large files as part of your playbooks and ansible repositories! If you need to distribute files consider using a remote copy from network shares (nfs/ftp/web) or from a binary repository
- Replace your “prompt” module usage with surveys, since “prompt” will not work in tower
- Monitor Ansible Tower
You should monitor the following components of Tower:
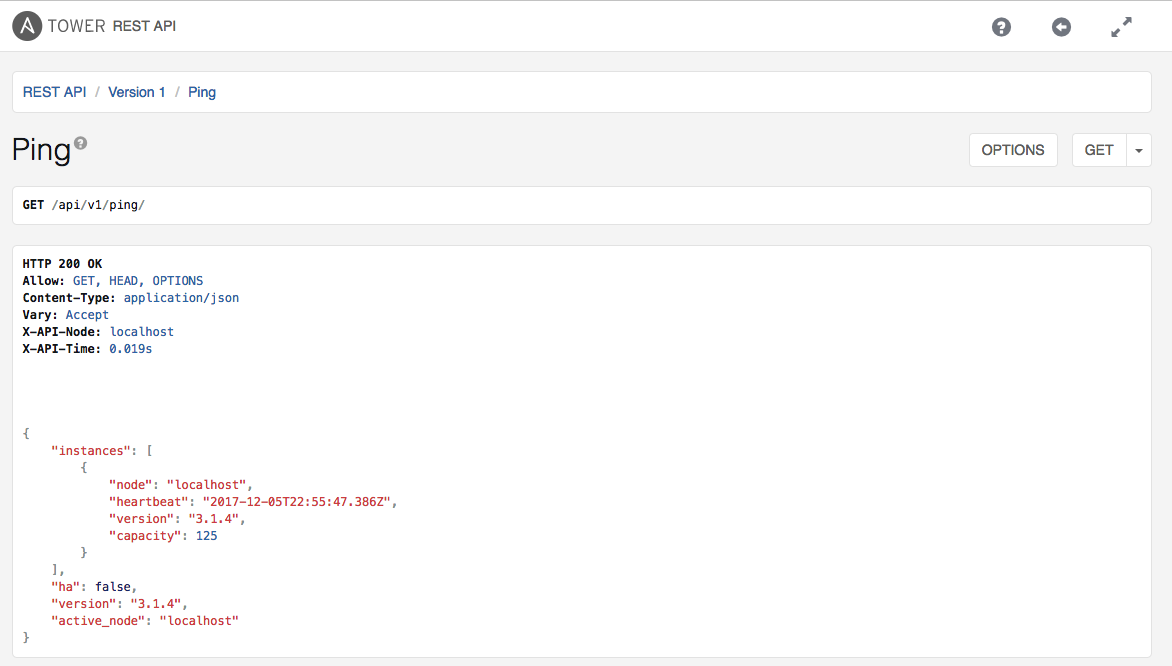
- API and Web Response (should also be use by LB VIPs):
- You should do this by monitoring the following URL in your Tower installations: https://tower-server-hostname/api/v1/ping
- If you have more than one Tower instance, you should monitor each one of the instances for a successful response (2XX).
- Check that RabbitMQ and Supervisord is running:
systemctl status supervisord; systemctl status rabbitmq-server - Main services in supervisord:
- aws-uwsgi, awx-daphne, aws-celeryd
- Logs:
/var/log/towerand/var/log/supervisor/
- Avoid the following things
- When you develop playbooks and roles, avoid using the following:
shell,command,raw, andscript. - Other modules should be used instead
- If you can’t avoid using one of this modules, test what you are executing and ensure that it is idempotent
- If you are using shell tasks as a handler, ensure that the task calling the handler comes from a module that is idempotent
- Modules that gather information should have check_mode set to “true” in order to be able to run them on check mode
- Do not use set_facts to set a fact that has been registered by another task
- Do not restart services without using a handler. Services restarts should always be done with a handler!
- Do not chain handlers! If you do, tasks may fail if a previous handler fails
- Not using dynamic inventory with Cloud providers
Thanks for reading and happy Ansible hacking!